For computational, statistical or display reasons, daily data are often aggregated to a coarser time scale. This is done by splitting the sequence into subsets along a coarser index grid, and calculating a summary statistics such as the mean value at each segment.
Missing values cause problems when calculating the mean. In the R default, the presence of a single NA returns an NA for most arithmetic operations. There is an option to calculate the mean after omitting the NAs. In the first case, the calculated means are valid but data is lost when converted to NAs. In the second, no data is lost but the means deviate wildly when the data come from strongly cyclical series such as temperature.

Figure 1 shows the reduction in monthly aggregate data when na.rm=T.

Figure 2 shows the reduction when na.rm=T, with almost total loss on annual aggregation. While data is not lost with the option na.rm=F, the outliers at the start and end of the Rutherglen minimum data series illustrates its unexpected biasing effect.
The figures illustrate that a heterogeneous sequence is not ‘invariant’ with respect to aggregation using a mean. The only way to ensure invariance, which confers a degree of reliability under aggregation, is if the missing data are randomly distributed within each section of the course index.
Most studies define rules about the number of allowable missing values, but either these are not clearly stated, or use rules that o not guarantee invariance, such as a set number of missing values (eg. CAWCR).
Because of the invariance of heterogeneous data under aggregation, it is best to analyze data at their original resolution.


 where
where 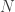 is the natural numbers, usually a discrete time step and
is the natural numbers, usually a discrete time step and  is a real number. A series is the progressive sum of the terms in a sequence
is a real number. A series is the progressive sum of the terms in a sequence  where
where  . A typical example of a series is the ‘random walk’ produced by the cumulative sum of random values. One occasionally sees more general series to model a given sequence, such the progression of higher order terms in a polynomial regression model
. A typical example of a series is the ‘random walk’ produced by the cumulative sum of random values. One occasionally sees more general series to model a given sequence, such the progression of higher order terms in a polynomial regression model  and the periodic terms of a Fourier series. A sequence space is a closed set of sequences; subtracting or adding sequences gives another valid sequence.
and the periodic terms of a Fourier series. A sequence space is a closed set of sequences; subtracting or adding sequences gives another valid sequence. . One of the main questions I want to address is how the analysis can be done reliably in the presence of arbitrary missing values.
. One of the main questions I want to address is how the analysis can be done reliably in the presence of arbitrary missing values.